My name is Olexandr Siroklyn. I am an Oracle database administrator, an UNIX system administrator, an Oracle SQL/PLSQL developer and a hobbyist C/C++ developer. I am also an Oracle 10g, 11g, 12c Certified Professional. My LinkedIn page is https://www.linkedin.com/in/olexandr-siroklyn-4a483615.
What is the purpose of this website? Its purpose is to demonstrate how to boost your Oracle database server by … for example utilizing the computational power of a video card or by any other findings. Let me elaborate on that.
Database part
Oracle Corp. proposes database version 12c in two editions, i.e. Enterprise edition and Standard edition 2. Hereafter I will be talking about Oracle 12c database Enterprise edition (ODBS EE) and Oracle 12c Database Standard Edition 2 (ODBS SE). More details and differences may be found here and here.
Without being lost in too much detail the three notes below are in order:
a. ODBS SE does not have parallel execution support for SQL/PLSQL and backup operations. ODBS EE does.
b. ODBS SE supports two CPU sockets only. ODBS EE has no socket restrictions.
c. ODBS SE is less expensive than ODBS EE.
Video card part
The heart of any video card is the graphics processing unit (GPU is the term I will use from here on). There are three top manufacturers of GPUs: Nvidia Corporation, ATI Technologies Inc. and Intel Corporation. Wikipedia says
GPU is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display. GPUs are used in embedded systems, mobile phones, personal computers, workstations, and game consoles. Modern GPUs are very efficient at manipulating computer graphics and image processing, and their highly parallel structure makes them more efficient than general-purpose CPUs for algorithms where the processing of large blocks of data is done in parallel.
What does this mean? GPUs found in modern video cards can crunch data faster than computer processor. But it makes no sense to perform elementary arithmetic operations like addition, subtraction etc. on two numbers using the GPU. Computer processor does it faster. But if you have 100 billion numbers, you force parallel computational mode and you’re going to calculate something more complicated than addition then there is a sense to use GPU. See please examples at GPU accelerated applications by Nvidia.
To summarize
My idea is this: ODBS (any edition) stores data. User connects to the ODBS and initiates computation on ODBS storing data via SQL language. The ODBS delivers data and description of computational operation to the GPU for acceleration precisely in parallel mode. The GPU performs computation and sends the result back to the ODBS, i.e. to the user. Below I demonstrate this idea’s proof-of-concept prototype.
ODBS SE case
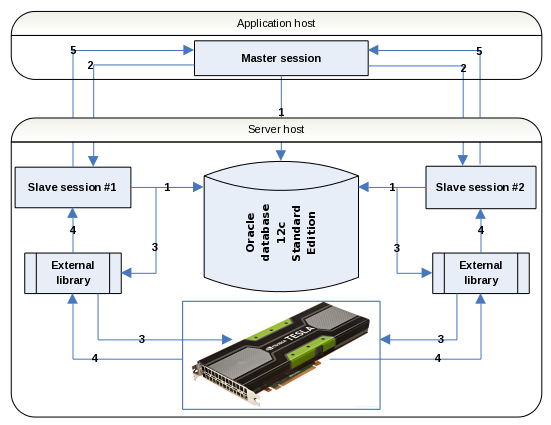
Algorithm
1. Master dedicated session and slave dedicated sessions connect to the database.
2. The master session sends a signal to start computations to the slave sessions(*) in parallel mode
3. The slave sessions extract data from the database and send it to the external library in parallel mode. The external library sends data to the GPU.
4. The GPU performs computation and sends result back to the slave sessions via the external library.
5. The slave sessions send result back to the master session.
* – a little bit odd multi-slave-session mode is initiated to eliminate ODBS SE restrictions: support of 2 CPU sockets only and non-parallel mode for SQL statements. Count of the slave sessions is limited only by the server host’s performance.
Prerequisites
Linux operation system with C and C++ compiler developer packages. Oracle 12c Standard Edition 2 database. Installed Nvidia based CUDA compatible GPU (see full list at CUDA GPUs or CUDA legacy GPUs). Installed Nvidia CUDA toolkit (version 4 or higher) that supports capability of your GPU from https://developer.nvidia.com/cuda-downloads.
It’s highly recommended to make sure the CUDA toolkit run-time libraries work properly. A way to do this is to build the toolkit samples (please refer to the Nvidia CUDA documentation) and to run after two programs from the CUDA toolkit catalog, i.e.
$ /usr/local/cuda/samples/bin/x86_64/linux/release/deviceQuery ... Detected 1 CUDA Capable device(s) Device 0: "GeForce 8800 GS" CUDA Driver Version / Runtime Version 6.5 / 6.5 CUDA Capability Major/Minor version number: 1.1 ... Result = PASS
$ /usr/local/cuda/samples/bin/x86_64/linux/release/bandwidthTest ... Device 0: GeForce 8800 GS Quick Mode Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 ... Result = PASS
Software installation
Please download an archive file file. Un-gzip and un-tar it. File contains installation scripts to create an Oracle package, a test table and a C++ source file to compile an external library. Please follow readme.txt file.
Test
I used Oracle Linux 6.8 (x64, 3.8.13 kernel), Oracle 12c Standard Edition 2 database, Nvidia CUDA toolkit v. 6.5/8.0. A test table contained 4194304 rows. Table is logically divided on two equal parts (because of 2 core CPU) via 1 and 2 values in a special column. Arithmetic operation was a simple addition of the integer numbers.
Results
Host A is equipped with an AMD E-450 (1.6GHz, 2 CPU cores) and a Nvidia GeForce 1050 Ti GPU. Calculation time with GPU usage is 7.02 seconds. Calculation time without GPU usage, i.e. plain SQL, is 0.61 second. Host B is equipped with an Intel Core2 Duo (2.33GHz, 2 CPU cores) and a Nvidia GeForce 8800 GS GPU. Calculation time with GPU usage is 3.01 seconds. Calculation time without GPU usage, i.e. plain SQL, is 0.35 second.
Conclusion
Technically it is possible to join an Oracle database and a GPU together. CPU socket and parallel restrictions can be easy overcome for Oracle 12c database Standard Edition. But there is a need to have a clear computational target for what to do all these things. The main performance bottleneck is a data copying from the Oracle database memory structures into the GPU memory. Overcoming of this is possible via C++ code optimization or increasing CPU/CPU core count. Approximately 32 slave processes on 32 CPU cores and therefore test table divided on 32 logical parts can give equal calculation time with and without GPU usage even for a simple number addition. But I have no hardware to test this.
Questions? Propositions? Comments? Let me know what you think via email
If some one wishes expert view on the topic of blogging afterward i advise him/her to visit this blog,
Keep up the pleasant job.
” The main performance bottleneck is a data copying from the Oracle database memory structures into the GPU memory.”
That’s going to be slow, but doesn’t have to be a bottleneck. By that I mean, don’t do that at the time you run the query. Imagine a system where you have a huge investment in multiple video cards and huge swaths of GPU RAM.
Say you have a 30GB table in Oracle, and also have a locally attached set of GPU with combined memory of 32GB (important thing, it’s big enough to hold the data).
Whenever you update this table, you sync it to the GPU copy. Let’s say that is done once a day at 2am.
Then, when the ad-hoc queries are run, there is no copying of data, that is already in sync. It is merely a trip to the GPU (or really the multiple GPUs) to ask for a result and return that.
For the reasons you’ve mentioned, copying data to the GPU is not worth it, might as well just run the query on the CPU. But if willing to spend enough to get a big GPU solution, then certain types of queries will certainly be faster, largely thanks to video card ram being faster than system ram.
Frankly if you are spending that type of cash you can get so much computing power, its not the compute that’s the advantage, its the super fast memory – system memory doesn’t touch that speed, today.
Hello Robert.
Thanks for your reply. But I suppose to spend money to buy a bunch of 32G GPU’s is equal to spend the same money to buy an Oracle enterprise license with a parallel SQL execution support 🙂
Interesting post, but I gave up from that idea when I saw it’s going to be through the external call and need to transfer data back and forth. Plus there are many restrictions of such approach and design of the external calls is old and not scalable.
That approach has been used before invention of Java Store procedures.
Hi Ivan,
Well I’m not sure if Oracle Java stored procedure and Cuda JAVA API (does it exist?) usage can give any acceleration. Even if it can a clear GPU computational target must be present and that is the problem.